Machine Learning
Maschinelles Lernen ist ein Bereich der Informatik, der es ermöglicht, Modelle zu trainieren, um Muster und Beziehungen in Daten zu erkennen. Der große Unterschied zum herkömmlichen Programmieren besteht darin, dass beim maschinellen Lernen anhand von unglaublich vielen Datensätzen (mit zugehörigen richtigen Antworten) Regeln erlernt werden, die dann auf neue Daten angewendet werden können, während ein Algorithmus anhand von festgelegten Regeln die Antworten findet. Folgendes Bild veranschaulicht dieses Konzept:


Umsetzung von KI-Projekten
Abschnitt betitelt „Umsetzung von KI-Projekten“Der Prozess des maschinellen Lernens ist im folgenden Diagramm dargestellt:
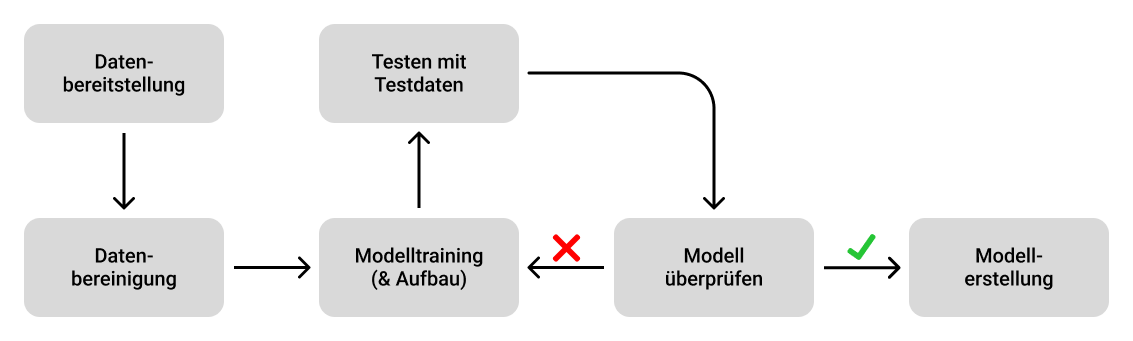
Wie man sehen kann, beginnt dieser Prozess mit dem Aggregieren der Daten und Bereinigung dieser. Auch wenn man es nicht glaubt, machen diese Teilaufgaben ca. 50-70% des Arbeitsaufwandes vom gesamten Prozess aus. Hierbei muss besonders auf den Datenschutz der Kunden, die Datenqualität und die Datensicherheit geachtet werden. Die Daten selbst können im Internet gratis oder kostenlos gefunden werden. Saubere Daten sind Gold wert!
Der eigentliche interessante Teil beginnt dann beim Aufbereitung und Trainieren des Modells mit den Daten und dem anschließenden Testen. Hierbei gibt es einige Methoden der deskriptiven Statistik, um die Qualität des Modells zu beurteilen. Sobald der Kunde mit dieser zufrieden ist, kann das Modell in der Produktionsumgebung eingesetzt werden.
Einordnung in die Kategorien
Abschnitt betitelt „Einordnung in die Kategorien“Maschinelles Lernen unterteilt sich hierbei in die drei großen Kategorien Supervised Learning, Unsupervised Learning, Reinforcement Learning.
-
Supervised Learning
Das überwachte Lernen kategorisiert alle Aufgaben des Maschinellen Lernens, bei welchem das Trainieren mithilfe von Daten und zugehörigen richtigen bzw. gewollten Antworten stattfindet. Das Modell wird demnach auf eine Art „Soll-Zustand“ hintrainiert. Um die Datensätze möglichst effizient zu nutzen, werden meistens 70% der Ursprungsdaten für den Prozess des Trainierens verwendet und die restlichen 30% für das Testen der Genauigkeit des Modells.Beispiele für das überwachte Lernen sind die Klassifizierung von Bildern, Texten, Sprache, Emotionen, die Erkennung von Spam-E-Mails, Empfehlungssysteme in Online-Shops oder gewissen Formen von Vorhersagen in bestimmten Bereichen.
Die größten Herausforderungen dieser Sparte sind das
OverfittingundUnderfitting. Aufgrund des Daseins der korrekten Antworten kann es geschehen, dass das Modell zu sehr and die Trainingsdaten trainiert wird und somit keine allgemein gültigen Regeln erstellen kann (Overfitting). Oder die Beschaffenheit der Daten, die falsch ausgewählte Architektur (Neuronales Netz) oder Algorithmus lässt keine allgemeinen Regeln erkennen (Underfitting).Nichtsdestotrotz ist das überwachte Lernen das weit verbreitetste und am häufigsten genutzte Verfahren, da es sich als sehr effektiv erwiesen hat.
-
Unsupervised Learning
Beim unüberwachten Lernen versucht der Algorithmus im Trainingsprozess die Daten in Gruppen zu clustern, um gemeinsame oder unterschiedliche Eigenschaften festzustellen. Dabei sind als Datengrundlage keine Antworten vorhanden und das Modell muss selbständig die Muster in den Daten erkennen.Diese Sparte ist vor allem in Bereichen des Clustern vorzufinden. Beispielsweise kann man unbeaufsichtigtes Lernen in Echtzeit nutzen, um Muster in Kundenmerkmalen (Marketingabteilung), Anomalien (Betrugserkennung), Empfehlungssystemen oder selten auf der Bildverarbeitung zu identifizieren.
Diese Art des maschinellen Lernens wird nicht so häufig verwendet, da die Interpretierbarkeit der Ergebnisse, die Skalierbarkeit und Komplexität oft zu großen Problemen führt. Erstaunlicherweise basiert unser Gehirn jedoch am ehesten auf dieser Methodik, da in unseren frühen Lebensjahren ausschließlich Rohdaten eingespeist werden (Hören, Sehen, Schmecken, …).
-
Reinforcement Learning
Das verstärkende Lernen ist ein iterativer Prozess, bei welchem das Modell mithilfe des Belohnungssystems trainiert wird. Das Ziel des Modells ist die Maximierung der Belohnung, welches mit dem Ziel der Programmierer (Maximierung der Genauigkeit) stark korreliert. Außerdem werden schlechte Belohnungen bzw. Bestrafungen vom Modell vermieden, was bedeutet, dass die Bewerter des Modells bereits in der Trainingsphase die Robustheit und Fairness des Modells sicherstellen kann. Somit kann diese künstliche Intelligenz schwer manipuliert werden, schädliche Informationen preiszugeben, und hat keine Vorurteile.Hierbei muss man bei der Implementierung des Learnprozesses jedoch aufpassen, nicht versehentlich das Belohnungssystem zu negieren. Dies ist nämlich wirklich einmal auch OpenAI passiert, weswegen GPT-2 das unanständigste Modell in der Geschichte wurde (YouTube).