Supervised Learning ist ein zentraler Bereich in der maschinellen Lernpraxis, der es ermöglicht, Modelle zu trainieren, um Muster und Beziehungen in Daten zu erkennen. Im Gegensatz zum unsupervised Learning, bei dem der Algorithmus versucht, selbständig Muster in den Daten zu identifizieren, erfolgt beim Supervised Learning das Training anhand von gelabelten Daten, die als Eingabe-Output-Paare vorliegen.
In diesem Kontext bezeichnet „gelabelte Daten“ eine Menge von Eingabebeispielen, für die die zugehörigen Ausgaben bereits bekannt sind. Das Ziel besteht darin, ein Modell zu erstellen, das in der Lage ist, aus neuen, bisher ungesehenen Eingabebeispielen korrekte Vorhersagen oder Klassifikationen zu treffen.
Es gibt verschiedene Arten von Modellen im Bereich des Supervised Learning, die jeweils für spezifische Aufgaben und Datenstrukturen entwickelt wurden. Dazu gehören lineare Modelle wie die logistische Regression für binäre Klassifikation, Support Vector Machines für marginale Klassifikation, Ensemble-Methoden wie Random Forests zur Kombination mehrerer Modelle, Naive Bayes für probabilistische Klassifikation und neuronale Netzwerke für komplexe Mustererkennung.
Der Trainingsprozess besteht darin, das Modell mit den gelabelten Daten zu füttern und die Gewichtungen oder Parameter des Modells so anzupassen, dass es in der Lage ist, aus den gegebenen Eingaben genaue Vorhersagen zu machen. Das trainierte Modell kann dann auf neuen, nicht gelabelten Daten angewendet werden, um Vorhersagen zu treffen oder Muster zu identifizieren.
Supervised Learning findet in einer Vielzahl von Anwendungen Anwendung, darunter Spracherkennung, Bildklassifikation, medizinische Diagnose, Finanzprognosen und vieles mehr. Die Wahl des geeigneten Modells hängt von der Art der Daten und der spezifischen Aufgabe ab, die gelöst werden soll.
Vorbereitung
Abschnitt betitelt „Vorbereitung“Train Test Split
Abschnitt betitelt „Train Test Split“In der Welt des maschinellen Lernens ist der Train-Test-Split ein entscheidender Schritt, um die Leistung von Modellen objektiv zu bewerten. Diese Methode ist von grundlegender Bedeutung, um sicherzustellen, dass ein Modell nicht nur die Trainingsdaten auswendig gelernt hat, sondern auch in der Lage ist, auf neuen, bisher ungesehenen Daten präzise Vorhersagen zu treffen.
## X und y erstellen## Kundenbewertungen (X)X = [ "Das Produkt ist wirklich großartig, ich bin sehr zufrieden!", "Leider entspricht das Produkt nicht meinen Erwartungen.", "Tolles Preis-Leistungs-Verhältnis.", "Ich bin neutral, es ist okay, aber nichts Besonderes.", "Schlechtestes Produkt, das ich je gekauft habe!"]
## Dazugehörige Kategorien (y)y = ["positiv", "negativ", "positiv", "neutral", "negativ"]
## DataFrame erstellenimport pandas as pddf = pd.DataFrame({'Bewertung': X, 'Kategorie': y})
## Daten in X und y aufteilenX = df['Bewertung']y = df['Kategorie']
## Daten teilen für lernen und validierenfrom sklearn.model_selection import train_test_splitX_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size = .3, random_state = 12)
print("X_train:", X_train.shape) ## X_train: (3,)print("y_train:", y_train.shape) ## y_train: (3,)print("X_valid:", X_valid.shape) ## X_valid: (2,)print("y_valid:", y_valid.shape) ## y_valid: (2,)Vektorisieren
Abschnitt betitelt „Vektorisieren“Beim maschinellen Lernens wird die Vektorisierung der Daten als wichtiger Schritt betrachtet. Die Vektorisierung ist ein Prozess, bei dem die Daten in Form von Vektoren umgewandelt werden. In diesem Beispiel werden die Textdaten mittels BoW vektorisiert.
from sklearn.feature_extraction.text import CountVectorizervectorizer = CountVectorizer()
vectorizer.fit(X)print("Token Count:", len(vectorizer.get_feature_names_out()))## <Anzahl unterschiedliche Wörter>
X_train_vectorized = vectorizer.transform(X_train)print("X_train_vectorized:", X_train_vectorized.shape)## X_train_vectorized: (<Anzahl Trainingsbeispiele>, <Anzahl unterschiedliche Wörter>)
print("Bag of Words\n", X_train_vectorized.toarray())## [Beispieloutput:]## Bag of Words## [[0 0 0 ... 0 0 0]## [0 0 0 ... 0 0 0]## [0 0 0 ... 0 0 0]## ...## [0 0 0 ... 0 0 0]## [0 0 0 ... 0 0 0]## [0 0 0 ... 0 0 0]]Lineare Modelle
Abschnitt betitelt „Lineare Modelle“Logistic Regression
Abschnitt betitelt „Logistic Regression“Support Vector Machines
Abschnitt betitelt „Support Vector Machines“Ensemble-Methoden
Abschnitt betitelt „Ensemble-Methoden“Random Forest Classifier
Abschnitt betitelt „Random Forest Classifier“Der Random Forest Classifier (RFC) ist ein leistungsfähiger und vielseitiger Algorithmus für Klassifikationsaufgaben. Er kombiniert die Vorhersagen vieler Entscheidungsbäume, um die Genauigkeit und Robustheit zu erhöhen. Die wichtigsten Vorteile des RFC sind:
- Robustheit gegen Überanpassung: Da jeder Baum auf einer zufälligen Teilmenge der Daten trainiert wird, verringert sich die Wahrscheinlichkeit, dass der Algorithmus zu stark auf Trainingsdaten angepasst wird.
- Stabilität und Genauigkeit: Durch die Aggregation der Vorhersagen vieler Bäume liefert der RFC konsistentere und genauere Vorhersagen.
- Geringere Varianz: Der RFC reduziert die Varianz, die bei einzelnen Entscheidungsbäumen auftreten kann, indem er die Ergebnisse vieler Bäume kombiniert.
- Automatische Merkmalsauswahl: Während des Trainings wird für jeden Split nur eine zufällige Untermenge der Merkmale betrachtet, was die Bedeutung irrelevanter Merkmale verringert.
Entscheidungsbaum
Abschnitt betitelt „Entscheidungsbaum“Ein Entscheidungsbaum ist die grundlegende Komponente eines Random Forest. Er besteht aus Knoten, die Bedingungen auf Merkmale der Daten prüfen, und Blättern, die die Vorhersagen enthalten. Der Baum wird rekursiv aufgebaut, indem an jedem Knoten der beste Split gewählt wird, der die Daten am besten trennt. Dieser Prozess wird so lange fortgesetzt, bis bestimmte Kriterien erfüllt sind (z.B. maximale Tiefe des Baumes oder minimale Anzahl von Datenpunkten in einem Blatt).
In der folgenden Abbildung sieht man ein Beispiel eines Entscheidungsbaums, welcher feststellen soll, ob eine Frucht essbar oder nicht essbar ist. Dieser Baum verfügt über einen Wurzelknoten, zwei innere Knoten und vier Blattknoten.
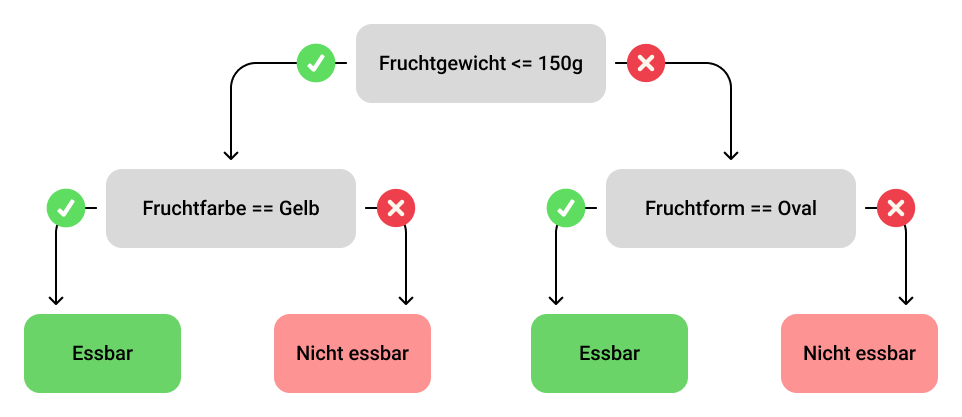
Ensemble-Lernen
Abschnitt betitelt „Ensemble-Lernen“Der Random Forest ist ein Ensemble-Lernverfahren, das viele Entscheidungsbäume kombiniert. Jeder Baum wird auf einer zufälligen Teilmenge der Trainingsdaten (mit Zurücklegen) und einer zufälligen Teilmenge der Merkmale trainiert. Die Vorhersagen der einzelnen Bäume werden dann aggregiert, um die endgültige Vorhersage zu machen. Bei Klassifikationsproblemen erfolgt dies in der Regel durch Mehrheitsabstimmung.
Im folgenden Bild sieht man anhand eines Beispiels, wie die Genauigkeit des gesamten Waldes aufgrund des unterschiedlichen Aufbaus der Bäume insgesamt steigt, da sich Fehler gegenseitig automatisch aufheben. Dieses Phänomen nennt sich Weisheit der Crowd.
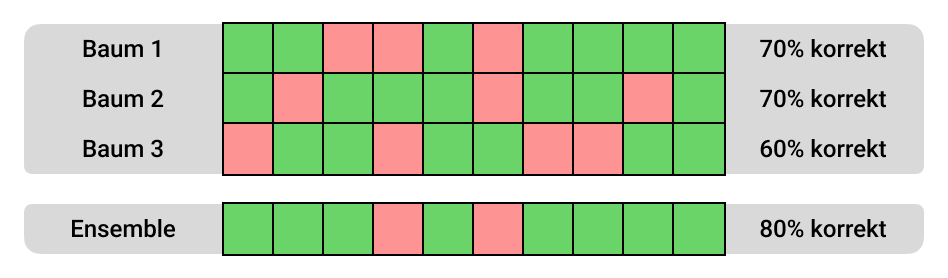

Codebeispiel mit Datenaufbereitung und Anwendung des RFC
Abschnitt betitelt „Codebeispiel mit Datenaufbereitung und Anwendung des RFC“Hier ist ein vollständiges Beispiel, das zeigt, wie man den RandomForestClassifier in Python mit scikit-learn verwendet. Das Beispiel umfasst Datenaufbereitung, Modelltraining und Vorhersage.
import numpy as npfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_score
# Daten ladeniris = load_iris()X, y = iris.data, iris.target
# Daten in Trainings- und Testsets aufteilenX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Random Forest Classifier erstellenclf = RandomForestClassifier(n_estimators=100, random_state=42)
# Modell trainierenclf.fit(X_train, y_train)
# Vorhersagen auf dem Testset macheny_pred = clf.predict(X_test)
# Genauigkeit berechnenaccuracy = accuracy_score(y_test, y_pred)print(f'Genauigkeit: {accuracy * 100:.2f}%')
# Beispiel-Vorhersage für neue Datennew_data = np.array([[5.1, 3.5, 1.4, 0.2]])prediction = clf.predict(new_data)print(f'Vorhersage für neue Daten: {iris.target_names[prediction][0]}')Genauigkeit: 100.00%Vorhersage für neue Daten: setosaErklärung des Codes
Abschnitt betitelt „Erklärung des Codes“- Daten laden: Das Iris-Datenset wird mit
load_iris()geladen. - Datenaufteilung: Die Daten werden mit
train_test_split()in Trainings- und Testsets aufgeteilt. - Modellerstellung: Ein
RandomForestClassifierwird mit 100 Entscheidungsbäumen (n_estimators=100) erstellt. - Training: Der Klassifikator wird mit den Trainingsdaten trainiert.
- Vorhersage: Vorhersagen für das Testset werden gemacht.
- Bewertung: Die Genauigkeit des Modells auf dem Testset wird berechnet.
- Beispiel-Vorhersage: Eine Vorhersage für neue, unbekannte Daten wird durchgeführt.
Dieses Beispiel zeigt die typischen Schritte zur Verwendung eines Random Forest Classifiers mit scikit-learn. Durch die Kombination vieler Entscheidungsbäume bietet der RFC robuste und genaue Vorhersagen und ist eine ausgezeichnete Wahl für viele Klassifikationsprobleme.
Gradient Boosting Classifier
Abschnitt betitelt „Gradient Boosting Classifier“Naive Bayes
Abschnitt betitelt „Naive Bayes“Naive-Bayes-Modelle sind eine Klasse von probabilistischen Klassifikationsalgorithmen im Bereich des Supervised Learning. Sie basieren auf dem Bayes'schen Theorem und gehen von der naiven Annahme aus, dass die Merkmale eines Datenpunkts unabhängig voneinander sind, obwohl dies in der Realität oft nicht der Fall ist. Trotz ihrer Einfachheit haben Naive-Bayes-Modelle sich als effektiv in vielen Anwendungen, insbesondere in der Textklassifikation, erwiesen. Diese Modelle sind schnell zu trainieren und zu implementieren, und sie bieten gute Leistung, wenn die Unabhängigkeitsannahme in der Praxis zumindest annähernd erfüllt ist.
MultinomialNB
Abschnitt betitelt „MultinomialNB“Multinomial Naive Bayes (MultinomialNB) ist eine Textklassifikationsmethode, die auf dem Naive-Bayes-Algorithmus basiert. Sie eignet sich besonders gut für Aufgaben wie Spam-Erkennung oder Themenzuordnung. Mit Fokus auf Wortzählungen in Texten ist MultinomialNB für seine Einfachheit und Effizienz bekannt.
from sklearn.naive_bayes import MultinomialNBfrom sklearn.metrics import accuracy_score
clf = MultinomialNB(alpha=0.2)clf.fit(X_train, y_train)
predictions = clf.predict(X_valid)print(accuracy_score(predictions, y_valid)) ## [Beispieloutput:] 0.9772727272727273K-nearest Neighbors (KNN)
Abschnitt betitelt „K-nearest Neighbors (KNN)“Neuronale Netze
Abschnitt betitelt „Neuronale Netze“Neuronale Netzwerke sind eine Klasse von Modellen im Bereich des maschinellen Lernens, die auf der Struktur und Funktion des menschlichen Gehirns basieren. Sie bestehen aus miteinander verbundenen Knoten (Neuronen), die in Schichten organisiert sind. Diese Netzwerke lernen durch Anpassung der Verbindungen zwischen den Neuronen (Gewichte), um Aufgaben wie Klassifikation, Regression und Mustererkennung durchzuführen.
Neuronale Netzwerke (NN)
Abschnitt betitelt „Neuronale Netzwerke (NN)“Neuronale Netzwerke bestehen aus einer Reihe von Schichten:
- Eingabeschicht: Die erste Schicht, die die Eingabedaten empfängt.
- Versteckte Schichten: Eine oder mehrere Schichten, die die Eingabedaten transformieren und komplexe Merkmale extrahieren.
- Ausgabeschicht: Die letzte Schicht, die das Ergebnis der Verarbeitung liefert.
Jedes Neuron berechnet eine gewichtete Summe seiner Eingaben, wendet eine Aktivierungsfunktion an und gibt das Ergebnis an die nächste Schicht weiter. Häufig verwendete Aktivierungsfunktionen sind die Sigmoid-Funktion, die Tanh-Funktion und die ReLU-Funktion (Rectified Linear Unit).
Neuronale Netzwerke lernen durch einen Prozess namens Backpropagation, der in Kombination mit einem Optimierungsalgorithmus wie dem Gradientenabstieg verwendet wird. Backpropagation berechnet den Gradienten des Fehlers bezüglich der Gewichte und Biases und aktualisiert diese, um den Fehler zu minimieren.
import torchimport torch.nn as nnimport torch.optim as optim
class SimpleNN(nn.Module): def __init__(self): super(SimpleNN, self).__init__() self.fc1 = nn.Linear(784, 128) self.fc2 = nn.Linear(128, 10)
def forward(self, x): x = torch.relu(self.fc1(x)) x = self.fc2(x) return x
model = SimpleNN()criterion = nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=0.01)Convolutional Neural Networks (CNN)
Abschnitt betitelt „Convolutional Neural Networks (CNN)“Convolutional Neural Networks sind eine spezielle Art von neuronalen Netzwerken, die besonders gut für die Verarbeitung von Bildern und anderen grid-basierten Daten geeignet sind. Sie bestehen aus:
- Convolutional Layers: Diese Schichten verwenden Filter (oder Kernel), die über das Eingabebild gleiten und lokale Merkmale extrahieren.
- Pooling Layers: Diese Schichten reduzieren die Dimensionalität der Daten, indem sie lokale Bereiche zusammenfassen, z.B. durch Max-Pooling oder Average-Pooling.
- Fully Connected Layers: Diese Schichten sind ähnlich wie in herkömmlichen neuronalen Netzwerken und verbinden alle Neuronen miteinander.
CNNs werden häufig in der Bild- und Videoverarbeitung, Mustererkennung und der Verarbeitung von mehrdimensionalen Daten eingesetzt.
import tensorflow as tffrom tensorflow.keras import layers, models
model = models.Sequential()model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.Flatten())model.add(layers.Dense(64, activation='relu'))model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])Recurrent Neural Networks (RNN)
Abschnitt betitelt „Recurrent Neural Networks (RNN)“Recurrent Neural Networks sind eine Klasse von neuronalen Netzwerken, die speziell für die Verarbeitung von sequenziellen Daten entwickelt wurden. Sie haben interne Speicherzustände, die Informationen über frühere Eingaben speichern. Diese Netzwerke sind besonders gut für Aufgaben wie Zeitreihenanalyse, Sprachverarbeitung und andere sequentielle Daten geeignet.
Varianten von RNNs sind:
- Long Short-Term Memory (LSTM): Eine spezielle RNN-Architektur, die entwickelt wurde, um das Problem des verschwindenden Gradienten zu lösen und langfristige Abhängigkeiten besser zu modellieren.
- Gated Recurrent Unit (GRU): Eine vereinfachte Version von LSTM, die ähnliche Leistungsmerkmale aufweist.
import torchimport torch.nn as nn
class SimpleRNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(SimpleRNN, self).__init__() self.rnn = nn.RNN(input_size, hidden_size, batch_first=True) self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x): out, _ = self.rnn(x) out = self.fc(out[:, -1, :]) return out
model = SimpleRNN(input_size=10, hidden_size=20, output_size=1)criterion = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.01)Transformer-Netzwerke
Abschnitt betitelt „Transformer-Netzwerke“Transformer sind eine neuere Architektur, die insbesondere in der Verarbeitung natürlicher Sprache (NLP) verwendet wird. Sie basieren auf einem Mechanismus namens Selbstaufmerksamkeit, der es ermöglicht, Abhängigkeiten über große Entfernungen in der Sequenz zu modellieren. Im Gegensatz zu RNNs verarbeiten Transformer alle Eingaben gleichzeitig und nutzen Mechanismen, die die Bedeutung jeder Position in der Eingabesequenz gewichten.
Die bekannteste Anwendung von Transformern ist das Modell BERT (Bidirectional Encoder Representations from Transformers), das Spitzenleistungen in einer Vielzahl von NLP-Aufgaben erzielt hat.
import torchimport torch.nn as nnfrom torch.nn import Transformer
model = Transformer(nhead=8, num_encoder_layers=3)src = torch.rand((10, 32, 512)) # (sequence_length, batch_size, feature_size)tgt = torch.rand((20, 32, 512))out = model(src, tgt)TensorFlow
Abschnitt betitelt „TensorFlow“TensorFlow ist ein Open-Source-Framework für maschinelles Lernen, das von Google entwickelt wurde. Es bietet eine umfangreiche Bibliothek für die Erstellung und das Training von neuronalen Netzwerken und ist besonders bekannt für seine Flexibilität und Skalierbarkeit.
Hauptmerkmale von TensorFlow sind:
- Tensors: Grundlegende Datenstrukturen, die n-dimensionalen Arrays ähneln.
- Graphen: Modelle werden als gerichtete Graphen dargestellt, wobei Knoten Operationen und Kanten Datenströme darstellen.
- Keras API: Eine hochstufige API, die das Erstellen und Trainieren von Modellen vereinfacht.
TensorFlow bietet Unterstützung für verteiltes Training, ermöglicht den Einsatz auf verschiedenen Plattformen (CPUs, GPUs, TPUs) und hat eine große Community sowie umfangreiche Dokumentation.
import tensorflow as tf
model = tf.keras.Sequential([ tf.keras.layers.Dense(128, activation='relu', input_shape=(784,)), tf.keras.layers.Dense(10, activation='softmax')])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])PyTorch
Abschnitt betitelt „PyTorch“PyTorch ist ein Open-Source-Framework für maschinelles Lernen, das von Facebook entwickelt wurde. Es ist besonders beliebt wegen seiner Einfachheit und Flexibilität sowie seiner dynamischen Computational Graphen.
Hauptmerkmale von PyTorch sind:
- Tensors: Ähnlich wie in TensorFlow, aber mit einer einfacheren Syntax.
- Autograd: Automatische Differenzierung zur Berechnung von Gradienten.
- TorchScript: Ermöglicht die Konvertierung von PyTorch-Modellen in eine Form, die in einer Produktionsumgebung ausgeführt werden kann.
PyTorch ist besonders bei Forschern und Entwicklern beliebt, da es intuitive und pythonische APIs bietet, die das Experimentieren und Debuggen erleichtern.
import torchimport torch.nn as nnimport torch.optim as optim
class SimpleNN(nn.Module): def __init__(self): super(SimpleNN, self).__init__() self.fc1 = nn.Linear(784, 128) self.fc2 = nn.Linear(128, 10)
def forward(self, x): x = torch.relu(self.fc1(x)) x = self.fc2(x) return x
model = SimpleNN()criterion = nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=0.01)